I hear “participatory” being thrown around a lot these days, including by myself. Participatory budgeting. Participatory democracy. Participatory modeling. Participatory development. It’s an idea I wholeheartedly strive for in my own work with governments and communities, with varying degrees of success and frustration. But what does this actually look like, for public digital infrastructure and the policies/programs that technology supports?
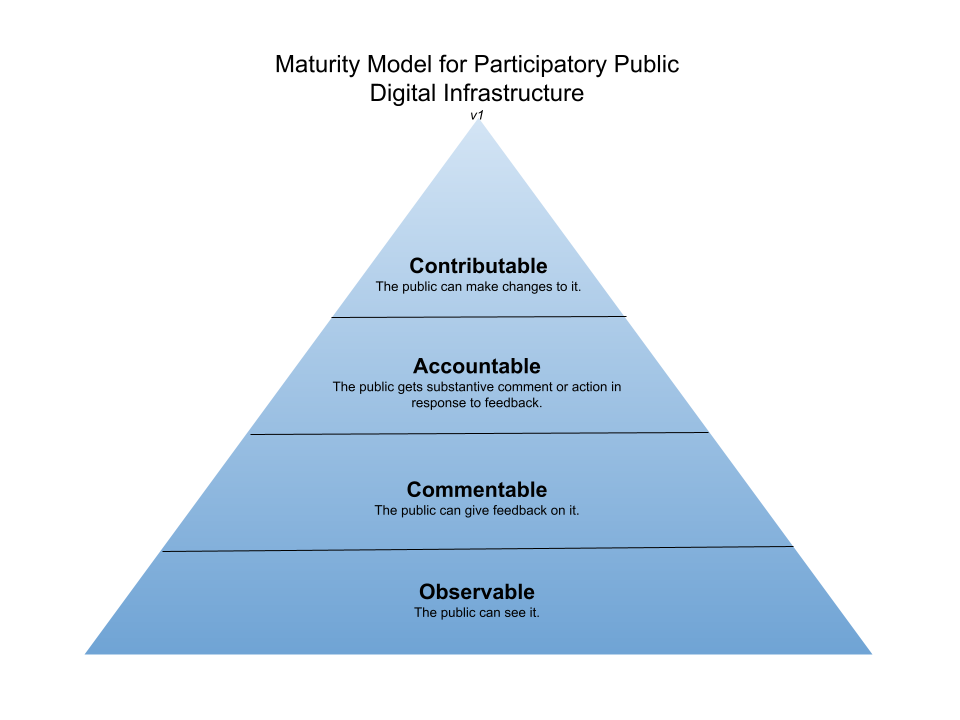
“Participatory” fundamentally means “affording the opportunity for individual participation.”1 I’ll let you dive into the links above for other examples of how to apply “participatory” to important public policy programs, but for tech, I’ve summarized how we can think about levels of participatory engagement in a maturity model, illustrated by this pyramid chart with a deliciously default blue gradient.
Level 1: Observable
As a foundation for any sort of more interesting or more meaningful participatory interaction, your tech has to be observable. That means the public can see it. To be clear, I don’t mean that the public can see and access every system the government makes from a user interface perspective – plenty of systems reasonably require users to create accounts and be authorized for access to data or pages. What I mean is that the code is observable, and it shows what was built and how.
For example, CDC’s PRIME SimpleReport app helps schools and other organizations report COVID tests to the proper authorities. Anybody can’t just open the app and see the live data being entered, BUT anybody can go see how the app was built by looking at its open source code.
Level 2: Commentable
The next level is commentable. This means the public has avenues for giving feedback on the product/tech/system. This could be a survey on the product’s website. It could be the Federal Register.2 It could be an email inbox or a public google group that people join and submit comments to. It could also be a code repository on a social coding platform like Github or GitLab, where the public can create issues (topics for discussion that may correspond to work to be done, such as bug reports or feature requests) and comment on issues or pull requests (a new chunk of code representing a new feature or bug fix, for example, that a contributor has requested to add to the code base that is now going through a review process).
It could also be a combination of some or all of the above, as is with the example of the Caseflow project from the Department of Veterans Affairs. There is a user support system that apparently gets channeled to the tech team, who created an issue on Github reporting the bug and opening discussion round the topic. Arguably, this gets into the next level, but I’m using this to show that you can include comments from other sources, not just your code publishing platform.
Level 3: Accountable
To get to level 3, you have to close the feedback loop and become accountable. Respond to public comments. Be able to point to precise changes that were made from feedback, such as adding a new feature, changing some text to plain language, fixing a bug, etc. If you can’t make the change requested, explain why. Nobody wants to speak into a black box – and nobody will take the time to do so if they don’t have reason to believe it will make a difference.
CMS’s open source Price Transparency Guide offers good examples of accountability using public discussion and linking questions and comments to pull requests representing work being done, such as this discussion, which coincidentally also discusses the (in)feasiability of open sourcing CMS’s 7 million lines of claims code, as well this issue, which links to pull requests addressing the problem.
Level 4: Contributable
Finally, you’ve hit peak participatory maturity when you’re able to and are actively accepting public contributions to your product. This is really the holy grail of participatory tech, and it’s what open source advocates have been dreaming about for decades. It’s incredibly difficult to achieve. To be able to even just accept contributions, you have to have the capacity to educate new contributors about the contribution process and conventions of your project to make sure their contributions are of high quality, and then to review requests to change code, content, or design, working with the contributor through any changes you want to see before you accept their request.
But even if you’re able to accept contributions, that doesn’t mean you will have people clamoring to submit them. A project I’ve helped lead, the Climate and Economic Justice Screening Tool, has been designed for Level 4 since the beginning, but even though we’ve had 75+ individuals attend meetings and participate in discussion at any given time, we’ve had only 4 people outside of the US Digital Service contribute code. We’ve had more people contribute research and analysis, as discussion on Github issues, in our Google Group, and in our ongoing catalog of the environmental justice data landscape – and these contributions are just as valuable as code.
Caveats
This model really only applies to singular products/projects/systems that have already been conceived of; it does not include considerations for a participatory process of originating a digital product/project/system. Multidisciplinary teams of program specialists and tech, product, and design staff should use iterative, human-centered design to work with users (i.e. members of the public) to identify what should be built and what that thing should do. User research, however, is not the same as a participatory process enabling members of a given community to identify what problems should be prioritized – this is more in the vein of participatory development, and worth more exploration later.
This model also doesn’t address the complexity of how to integrate participatory policy with participatory tech. In my experience, this is one of the hardest things to do.
Let’s say you have a system that hosts an algorithm identifying communities that are eligible for a specific grant, for example. If someone from the public can see this code and comment on a part of the algorithm they disagree with, who should respond? The tech product team building the system, or the policy makers deciding what the algorithm does? If someone identifies a bug in the algorithm and submits a fix, but that fix removes 20% of the communities identified, does the tech team decide to accept the fix, or does the policy stakeholder need to approve or reject it first? How is that communicated?
What this indicates is that you can’t separate the tech from the programs or policies it is designed to support, and teams need to be working closely together towards the same outcome goals and with a shared understanding of how participatory engagement should shape the program and its delivery. The example of CMS’s Price Transparency Guide and attempts to codify rules as (open source) code are efforts that directly tackle this bridge, but in many cases we’re still far from it.
Finally, public digital infrastructure can only be as participatory as the public has capacity to participate in it. To achieve real equity and quality in engagement, we have to invest in communities, especially overburdened and underserved ones, to build capacity, tech/data literacy, and policy literacy.
1
From an online dictionary. As a side note, it’s annoyingly difficult to make a noun out of – do we really want to say “participatoriness?” Ah well.
2
No offense, but whenever I look at the density of text and comments on the Federal Register, my brain shuts down. I'd love a more public friendly UI for a public comment system. Also, I don't think a government staff member can give responses to comments on the Federal Register, which is a blocker to reaching level 3.
In the spring of 2020, I started working on pandemic response projects as part of my tour of service with the US Digital Service. When we tried to solve the problem of getting better public health data faster to folks who needed it for the response, we traveled to multiple states to speak with local and state public health officials and understand what their concrete technological, organizational, and regulatory barriers were to collecting and sharing pandemic data amongst themselves and with federal teams.
We heard a common refrain: “We are over capacity, and we need help. Not just money, or rules, or requests for data. Help.”
What I began to realize over the subsequent two years was that I was witnessing the beginning of what I believe—and hope—to be a seismic shift in the relationship between the federal government and constituent governments such as states, territories, tribes, and localities. I describe this shift as one to servant leadership.
A few years ago, I worked in a company where “servant leadership” was all the rage. The idea was that managers should seek to serve their team, and not the other way around: they should help their employees do their jobs to the best of their ability, not just set goals and performance metrics and walk away. This resulted in teams being more effective and employees being happier, because we were all working together to set goals that were achievable, with managers having a clearer understanding of what went into achieving them. Managers also started being proactive about helping with small or mundane things, or removing blockers, so that employees could focus on what they did best, the skills that were the value they were bringing to the team, and thus to the company.
This does not describe the historical dynamic between the federal government and states/territories. Some might even balk at my implication that the feds are “managers” of states. However, I think the analogy stands: the federal government acts (or should act) as leaders amongst the constituent governments, by setting nationwide policy goals, funding programs that further those aims, and holding states accountable to meeting important goals, standards, and regulations, such as accessibility or equity requirements, typically through monetary penalties. In other words, the feds say, “Here’s what we want you to do, here’s a pile of money, and here are the rules. Now, go.”
What would it look like if the federal government took on a servant leadership philosophy in working with states/territories implementing federally funded policy and programs?
Instead of simply adding strings and a vague direction to the purses they hand out, what if they worked with these smaller governments to set achievable goals and proactively provide support to achieve them, in the form of useful resources, shared services, and, simply, help?
Now, I understand this question of the relationship between federal and state/territorial governments is a fundamental one that Americans have been debating for centuries. Is there federal government there for national defense and maintaining a really old, rarely refactored document that’s supposed to enshrine civil rights? Or is it there to help people and actively protect (and maybe even advance) those rights? I am not a constitutional lawyer nor do I hold a PhD in American history or public policy. I can only speak from my own experience working in and around government and community organizing for ten years.
What I have seen is this: the federal government has left a huge gap in digital public infrastructure (including software but also knowledge, best practices, user research, etc), and states are realizing the gross inefficiencies of going it alone and outsourcing all of that individually to vendors who are incentivized by profit, not public interest. As a result. people in the real world are getting the short end of the stick with poorly designed public services and even more poorly built technology supporting those services. This is especially problematic in this increasingly mobile and online world where people might live, work, travel, or care for family in multiple states all at once, but where there is poor interstate digital infrastructure.
It’s time we invested in our federation and the infrastructure we need to hold it together–and servant leadership from the federal level is a critical part of that.
While this idea is not yet common, fortunately it’s not new, and it’s gaining ever more momentum with federally funded programs since the pandemic started. In the nondigital space, the classic example of centrally designed and supported infrastructure is the national Eisenhower Interstate System. Another example someone in the open source policy space recently shared is that of the National Archives: while the Archives’ mission is the preservation of federal records, it also embodies servant leadership by supporting state archival efforts through open source software, resources, events, and programs, in addition to the more typical grants.
Meanwhile, the Office of the National Coordinator of Health IT, originally created in 2004 by the Bush administration and legislatively mandated in 2009 as part of the HITECH Act, serves in an even more explicit servant leader role in the digital space. Part of the Department of Health and Human Services, ONC’s job is to advise, coordinate, and support with health information technology across all levels of government, including the creation of state health information exchanges (HIE) – not to mandate or regulate how states spend money. ONC helps states who want to create an HIE with strategy, technology, and interoperability, and they have good relationships with these states and their HIEs because of this type of partnership.
ONC is an example of how the federal government has invested in an entire department that exists to help states create infrastructure, and provides strategy, policy, standards, and tech (things I would also include in the umbrella of “infrastructure”) as part of this support. This isn’t common. Federal agencies often tend to outsource support, knowledge, and interstate digital infrastructure to the private sector, typically in the form of major national nonprofits or associations of state/territorial governments. For example, the National Association of State Workforce Agencies (NASWA) receives federal funding to provide IT support and products for state unemployment insurance technology.
Federal government also provides support to states through “technical assistance,” whereby a federal program dedicates a pot of money or a host of contractor teams reserved for helping states with some aspect of implementation, either by running the contractor teams themselves or paying private organizations like the ones mentioned above to run them. From what I’ve seen (and I’ve by no means seen them all!), these programs have a variety of results and implementation details, but they tend to be one-off efforts or grants and unfortunately too often any learnings gleaned from an effort stays within the recipient state or within the minds of the contractors deployed there. There is a huge opportunity for technical assistance to also act as user research and feed into a broader program strategy that reuses lessons learned, processes or software developed, informs the development of a shared service or infrastructure component, and even influences program policy based on findings from the reality of implementation.
The momentum is building for the feds to take more ownership of the support and shared infrastructure (including knowledge, software, and services) they provide to constituent governments. The Department of Labor, for example, is piloting an initiative for unemployment insurance technology that embodies this perfectly. Their program includes deploying new software in Arkansas and New Jersey, sharing best practices and lessons learned from those and other states, and publishing open source reference implementations to inform better UI tech.1
The Centers for Disease Control and Prevention (CDC), in partnership with the US Digital Service has also launched new public health infrastructure and support projects over the past two years, under the Pandemic-Ready Interoperability Modernization Effort (PRIME) initiative.2 This effort has included trying new tactics for technical assistance as well as helping states set up critical public health infrastructure that is interoperable with other states’ and federal systems, so that states can not only meet federal requirements for COVID (or other infectious disease) reporting but also help states meet their own reporting needs and achieve their own public health goals.
I’m excited that DOL and CDC–and I’m sure other federal agencies I haven’t noted here–are taking on more of a servant leadership role with states, territories, tribes, and other governments and communities. I want to see folks at all levels of government working together to understand user needs and priorities (where users are the public as well as public servants), set goals collaboratively, and then create and share knowledge, best practices, code, and other services and infrastructure to help those governments reach those goals, save time and money, and ultimately improve the lives of the people.
I’m guilty of telling people, especially in government, to “do open source.” I know, I know, I’m sorry. It’s good advice, obviously, but it’s also vague and broad. It means something different to everyone.
Plenty has been written on the boons of open source in government, and I’m sure we’ll be writing plenty more. But first, it’s time to unpack the verb “do” and clarify what this encompasses. When we talk about “doing open source,” we generally mean one or more of these three verbs: USE, MAKE, and CONTRIBUTE.
USE open source software
Anyone can use open source software. Most people already do. Use the internet? You’re almost certainly using open source software – your browser itself might be open source (Firefox) or built on open source (Chrome, built on Chromium), or you’re looking at a web page that uses open standards such as HTML or CSS. I know open standards aren’t technically open source software, in the sense there isn’t source code to be open, but I typically lump them together in the same boat because they are open for anyone to use and they are built with similar practices and processes as open source software (e.g. you can contribute to HTML on Github).
In addition to relying on open standards to be useable, chances are, any webpage you’re on was built with open source software as well. So many languages used to build web applications are open source: Wordpress (which is used by 64.5% of websites using a content management system), JavaScript libraries such as jQuery or Node.js, Ruby or RubyOnRails, Rust – to name a few you may have heard of.
When we talk about using open source in government, sometimes we mean using an end application with a user interface (e.g. an open source map tool) but usually we mean using code libraries or languages that are open source by incorporating them into another software project. You can make a website that is not open source but uses many open source libraries, because they are utilities or tools rather than the end product. Almost everyone does this, unless they’ve been locked in to a vendor situation and can’t get out. It isn’t controversial anymore, since open source software (and open standards and programming languages) now pretty much powers the digital world. Open source software is a utility, and it’s ubiquitous.
MAKE open source software
Technically, to make open source software, you don’t have to do anything but slap one of these licenses on your code that allow your software to be freely used, modified, and shared. Does anyone else need to be able to find or see your code? Nope. Example? I can think of tons from government (I won’t name names), where I’ve been told something is “open source” and when I ask to see the code, either no one can find it or someone emails me three weeks later with a zip file full of millions of lines of Java. If you can’t tell, I am not a fan of this meaning.
To make open source software in a functional sense and not just a technical sense, you have to license your code appropriately and make your code publicly available and discoverable. I believe that software paid for by the public should (except in certain circumstances) live in the public domain, but if the public can’t find it or view it, is it in their domain? Furthermore, some of the benefits of making open source code such as enabling reuse, providing transparency and accountability to algorithms, and facilitating contributions from the public (more on contributing below), are nigh on impossible without the code being available publicly online.
People sometimes make their code publicly available on the internet and don’t use an open source license, either intentionally, like Mapbox, or because they forget (totally guilty here!), so always be sure to look for the license is you’re about to use code you’ve found online, and don’t forget the license on your own projects.
CONTRIBUTE to open source software
Contributing to open source software, while not a necessary part of using or making it, is a key way to unleash the value of open source software. For government, this could mean that your team contributes back to the open source software it uses, and/or that your team allows the public to contribute to the open source project that it makes.
Contributions don’t have to be code: they can be reporting bugs, adding or fixing documentation, answering questions on Github issues, translating content, or even providing money to the open source maintainer team or governing body to support continued development.
Individuals working on government teams should be encouraged to contribute back to open source software that the team uses, because it helps make the software better and ultimately makes that team’s end product better – and even more secure. One example of government already doing this is QGIS, a popular free and open source geographic information system. Although QGIS is not a government-created or -maintained tool, the changelog shows new features that were developed by or funded by local and national governments over time.
The recent log4j vulnerability highlighted the value of contributing back to open source: maintainers of this critical open source library that used by many federal agencies are volunteers, and if the government were to invest resources into supporting this project or others that it uses, then they could help identify and mitigate vulnerabilities more quickly. Contributing to open source is investing in digital infrastructure.
Likewise, government teams can realize a huge amount of value by supporting public contributions. The US Web Design System, an open source project includes design components, tools, and guides for government agencies to use in the design of their websites, has over 150 contributors – way more than the number of staff actually on the project. This sort of value isn’t realized overnight, and empowering external contributors takes substantial work in the form of good documentation and a responsive team, but it’s a worthwhile goal for many government projects.
Header image attribution: "Dictionary" by greeblie is licensed under CC BY 2.0.
Unemployment insurance (UI) modernization has been a hot topic since millions of Americans had to apply for unemployment benefits—many for the first time—using largely archaic, complex, and unstable state systems during the COVID-19 pandemic. Many states and the federal government have known for years that these systems were vulnerable and needed a refresh: 24 states began or completed modernization projects for their UI benefits and tax systems between 2000 and 2021, with varying levels of success, and federal money has been going out the door specifically for such projects since 2009, when Congress passed the UI Modernization Act.
Unfortunately, even “modernized” systems completely fell over during the pandemic. Expert organizations have published valuable playbooks and resources to help address key problems with these systems (e.g. lack of human centered design, no user testing before launch, etc), and I encourage folks to check those out if you want to get into the weeds of better UI tech or learn from UI as a case study in how federal programs are implemented at the state/territory level.
As part of my work with the Intergovernmental Software Collaborative at the Beeck Center, I wanted to look at improving UI tech through the lens of collaboration between jurisdictions – between peer (state/territorial) governments as well as between the federal Department of Labor and states/territories. I found three promising pathways for collaboration that already have some precedent to learn from and build on: consortia, federal shared services, and communities of practice.
Read the white paper to learn more about each of these approaches.
Tl;dr? Here are some key takeaways:
Let outcomes and user research drive the collaborative project/product (duh)
Feds should invest in open shared services and shared knowledge
Communities of practice of state practitioners are incredibly valuable when invested in and proactively managed
I hear people in government talk about software maintenance a lot. What they usually mean1 is they have paid for a software application to be built by a contractor and now they want to put it on a shelf and pay someone (possibly a different contractor) to dust it off every now and then. Maybe they’ll even pay someone (very possibly yet another contractor) to be on hand should that application fall off the shelf and break – but only if this happens during business hours (9-12pm and 2-5 ET, Mon-Fri).
Now, if you’re in the private tech sector, you’re probably confused. That doesn’t sound like product development, you might be thinking, and you’d be right. This isn’t product development, and unfortunately, it’s often not even what you might consider product support.
When companies in the private sector treat their products like this – as something to be built once and then “maintained” – these products eventually lose all their users. Sometimes companies put legacy products on life support because they intend to deprecate the product and ask their users to move on by a specific sunset date. For the rest of them, however, they lose users because their users find a better alternative that meets their evolving needs.
The government rarely sunsets products or processes. Let’s be real: we’re talking about an organization that still requires employees to fax HR paperwork.2 Users also rarely have alternatives, except for when private industry comes along and convinces them that they should pay for basic services (e.g. filing taxes) or when nonprofits emerge to help with basic social needs (e.g. protecting against housing discrimination).
But just because users can’t really leave doesn’t mean they don’t matter. With government products, the users are the public, are the customers, are the tax payers. Government loses money and trust when it doesn’t solve real problems, respond to user needs, and demonstrate value. And spending a lot on software that sits around gathering dust and losing users or causing more frustrated users is rather expensive and doesn’t serve the public.
So, rather than think of software as something static to be maintained, let’s think of software as a product – in govtech, usually a product whose users are either the public or government users facilitating service delivery. The key product idea to keep in mind is that the technology isn’t the end goal: solving a problem is the end goal.3
When you’ve built a software application, you don’t measure its success by how often it doesn’t fall over – a.k.a. how well it is “maintained” – but by how well it solves the problem you built it to solve.4 This involves understanding users and their problems, setting goals, and building towards those goals. It involves constantly monitoring and assessing the product and its performance towards those user-centric goals. That involves continuing to stay in touch with and understanding users.
Example: Applying for a driver’s license
The problems related to this process vary from state to state, and I’m not going to pretend to be an expert. But I have been in many a DMV (Dept. of Motor Vehicles) and applied for a driver’s license in 3 states, and, as a user myself, I’ve experienced some problems. One big one I’ve faced across all three states is that it takes quite a long time to apply for and receive a driver’s license. Most recently it required multiple trips to the DMV, and at the last one, I filled out a form in person and then watched the person behind the desk type it up for me before having me double check that it was correct.
If you were the product manager for the DMV,5 you’ve got multiple users to think about (driver’s license applicants, DMV staff, DMV executives, etc), but in this case let’s just focus on the public user, the driver’s license applicant.
For this problem, you’ve also got multiple metrics you can look at, but for simplicity, you could identify one key metric and set an objective for it: the time it takes an applicant to get a drivers license from start of application to receiving the license. You want to decrease this time.
You’ve identified the users, problem, and measurable objective, so now you follow human-centered design principles and determine that most of the time is taken during compiling the right documents, filling out forms, and visiting the DMV. So you build an online application product that allows for complete online submission of the paperwork so users can make a trip to the DMV for just their signature and photo. Lo, after user testing and deploying the product, you find that you hit your objective. You conclude that your product successfully addresses the problem for driver’s license applicants applicants.
But you can’t stop there. And you can’t just think of future work on this product as maintenance in the form of bug fixes, security, and system uptime.
Users change. They change in demographic makeup and how they use technology. Half of users may use this product on mobile today but next year? Maybe that’s up to 75%. If users change, their problems probably change too. In this case, hell, with the promise of autonomous cars, users are probably going to change how they use cars in the not too distant future – and what will that mean for driver’s license applications and this product you’ve built?
Technology changes. What worked on Internet Explorer 6 may not work on the latest version of Firefox. What worked on desktop may not work on mobile. What is the most efficient and secure programming language or framework today won’t be in 2-5 years, much less 10 or 20 years from now.
Policy changes. Requirements might be added or removed from the application process. Policy might even come down that mandates how quickly the DMV must process applications, which might affect how you think of product success.
Maintaining software isn’t good enough. From the time of design, development, and launch, the software you’ve built is a living part of how you deliver services, and should be constantly evaluated and evolved alongside the evaluation and evolution of your agency’s service delivery as a whole – which should include assessing customer satisfaction, impact, efficiency, and other metrics and goals.
You might even find that your technology solution no longer helps your agency’s overall goals or solves your customers’ problems – in which case, don’t be afraid to sunset the product, document your learnings, and iterate on a new solution.6
1
Usually, but not always! There are amazing people in govtech implementing more effective product development approaches. #NotAllGovTechies
2
True story: I sent my first ever fax last month.
3
This is usually true in the private sector too, except in cases like the Yo app.
4
Although, yes, system performance and hitting metrics defined in service-level agreements (SLAs) are both important.
5
Wouldn't it be cool if DMVs had product managers?
6
In government and looking for something to sunset? I vote starting with the fax. And sending user passwords by physical mail. And websites that only work in Internet Explorer. See, there are so many things ripe for deprecation!
I’ve been working on organizing some departmental knowledge at CMS, and our human-centered design team – the crew that promotes design thinking and helps other teams build better, more user-focused products and processes1 – recommended that my first step be to get teams to make directories. It’s a huge task to get everyone to use Confluence or to use it consistently. Instead, make sure each team has one Confluence page that links out to everything someone might need, and keep a central directory linking out to those team’s directory pages.
Directories aren’t just useful to collect resources in a collaborative team setting. Google found success in being the biggest, baddest directory2 of the World Wide Web in the whole wide world. Its premier product is essentially a list of links to other pages on the internet. The web wouldn’t be what it is today without lists of links, and without people or programs making lists of links.3
This isn’t a new concept: tables of contents and indices in the backs of books have been providing lists of links for millennia.4 Tables of contents, indices, directories, catalogues, registries, etc – these are all about empowering the user. Do you think you know what people are looking for? You don’t. That’s why you have to empower people to find it themselves and access what they find. In other words: You need to give them a list of links – and maybe a decent search function.5
In the context of government, it may seem like a no-brainer that a government website should have directories: a directory of all the services offered by that agency, or a directory (a.k.a. sitemap) of all the pages you can find on that website. Indeed, most government websites have these things. In fact, this may seem so obvious you’re probably wondering why I’m writing about it.
The thing is, when it comes to APIs and specifically government APIs, we don’t see a lot of directories.
Right now there is no complete (or even partially complete) authoritative list of US federal APIs. Here’s what does exist (that I could find this weekend):
18F used to maintain a list of federal developer hubs, which is a pretty decent substitute for a list of federal APIs. An organization’s developer hub would typically list all of that organization’s APIs; however, this isn’t always the case. Furthermore, the Github repository for the website’s code has been archived, and the last update was made in September, 2018.6
Programmable Web’s Government category in their API directory currently contains 772 APIs. However, these include APIs from governments across the world (e.g. Singapore and New Zealand) as far as I can tell, there’s no way to filter these by country. Furthermore, some of these APIs are not published by governments but by private companies or other organizations.
The next closest thing I could find is data.gov. Notably, data.gov is the US federal directory for open datasets, and datasets are not the same thing as APIs. APIs are complete software products: they have a full lifecycle from strategy and design, to testing and deployment, to marketing and change management. Plus, they can be transactional, allow you to send data back (a.k.a. “write” APIs), or provide services (e.g. enabling you to submit a FOIA request via API). Some of the datasets linked to from data.gov are available via APIs, in addition to being available as flat file downloads. You can specify “API” in the data directory to find these.7
I’ve done some research into other government API directories as well, and haven’t come up with a whole lot. Here are a couple:
New Zealand has an API catalogue that you can search, and when you select any API, you are directed to a page with both documentation and an API console rendered from the API’s OpenAPI definition.
API directories are important because APIs are products. An API directory is a product directory: you can think of it as both an inventory for the business owner and a catalogue of available products for the customer. Governments should have directories of their API products so that they themselves know what they have across different silos (a.k.a. agencies and departments) and can begin to collaborate and share knowledge (and eventually infrastructure), and so that the public can discover and use services and products offered as APIs.
You know that feeling when you go to an ice cream shop and want mint chocolate chip but it’s not on the menu, so you settle for chocolate chip cookie dough, only to find out after you’re halfway through that the shop had mint chocolate ship all along? Or you find out the shop had extra rich, dairy-free dark chocolate sorbet, which you’d never heard of before but definitely would’ve ordered if you’d seen it on the menu? Yeah, you feel a bit cheated, but in a way where no one wins.
That’s how I felt when I discovered the NPPES API, CMS’s provider lookup API: I had already seen CMS’s developer portal and thought I knew what was on CMS’s menu, only to discover this other API weeks later in a meeting. Needless to say, the dev portal does not list the NPPES API.8
Why are API directories so hard?
People have been trying to build API directories for years. Programmable Web, RapidAPI, and others have API directories of varying levels of freshness and accuracy. It’s hard – especially when you’re relying on humans to create and maintain these directories. There are so many APIs, and they change: they get new versions, or they get deprecated, or their documentation moves to a different URL. It’s a lot to keep track of.
Wouldn’t it be great if we could automate creating and maintaining API directories somehow?
Luckily, people have been working on ways to do just that!
APIs.json: This project, started by the API Evangelist and 3scale, aims to create a standard, machine-readable way for API providers to describe and share their API operations, similar to how web sites are described using sitemap.xml (which is a pretty standard part of websites now). You can search APIs that are described by apis.json files at the related search engine project: apis.io.
JSON Home: Similar to the above, this project aims to provide a standard for machine-readable “homepages” for JSON APIs.
The goal with both of these standards is that you can figure out what APIs are offered by a given company or organization simply going to the API homepage. That homepage is essentially a directory of the APIs available with links to the documentation of each API.
How can we get to maintainable, sustainable government API directories?
Many governments already have API standards and guidelines that they publish and – hopefully – adhere to. I would like to see each of these documents include a requirement that agencies keep an up-to-date machine-readable directory of their API offerings that link to the OpenAPI (or other standardized) definition for each API. One way they could do this is having an APIs.json file life at agency.gov/apis.json – or, they could use JSON Home or other emerging standards for machine-readable API directories.
The idea is, if you are a central government and you have some agencies publishing APIs, they could list their APIs as data in a machine-readable format on a URL that they’ve given you that doesn’t change, and then you can have a website that grabs that data from those URLs in real-time. Then, you can display the data however you like – maybe you jam all these lists into one list and display the list with pretty styling and let users search by keyword or filter by agency. Then, BAM, you have a centralized API directory that gives a coherent and accurate picture of all the APIs provided across your agencies, and all you had to do was add the agencies’ directory URLs to your website’s list of URLs to get data from.
Some governments and agencies already require API providers to register their APIs, though this isn’t currently requird to be in machine-readable formats:
I was excited to read that data.gov is already pushing a similar initiative for open datasets: All agencies by the end of 2020 have to publish catalogues of their datasets at agency.gov/data and each dataset or data API offered by an agency must be described by a standardized data.json file that contains metadata. This makes automated discoverability and maintenance of the federal data directory not only possible, but easy. Let’s work towards making this same principle a reality for government APIs as well.
1
Interested in how we use human centered design at CMS? Read about it on the USDS blog.
2
Other superlatives we could add: Creepiest, greediest, megalomaniacalest, etc.
3
Unfortunately, Google's dominance as The Directory of the Internet is often a big deterrent from people making their own.
4
According to Wikipedia. Wikipedia is another great example of a product using links to help people find what they’re looking for -- and things they weren't. Alas, the many hours lost to Wikipedia rabbit holes.
5
Wondering what to get me for my birthday? That’s right - give me a list of links, maybe one with links to cool things to do in DC, because damn is it hard to find non-museum or non-institution events in this city.
6
Interestingly, it looks like they'd had other ideas for creating a canonical list before, based on this old, never completed Github repo.
7
But this isn’t really a directory of the sort I’m looking for, and it appears only two departments publish APIs to this catalogue. These APIs are open data APIs and some of these APIs use HTML as a content type, so can these even be called APIs?
8
To be fair, the NPPES API replaces a data download, so the providers may be thinking of it more as an open data offering than an API product, but still -- this is an API I'd like to use in a real-time manner, and if I hadn't been in the room to hear someone mention it, I would not even have known about it.
Hello, internet, my old friend, I’ve come to talk with you again. Not about visions softly creeping, leaving seeds while I was sleeping. No, I haven’t been sleeping – I’ve barely had time to, between all the work I was doing in 2019 and the number of times I listened to this Simon and Garfunkel album on repeat.1 It turns out I have a hard time saying no to interesting projects – and I’ve been focused more on doing than on writing about what I’ve been doing. Now, it’s time to reverse that trend, and disturb the sound of silence.2
2019, phew
I’ll start with my biggest news of all: In the fall, I moved to Washington, DC, to start a “tour of civic service” with the United States Digital Service (USDS). I’m working with the Centers for Medicare and Medicaid Services to help fix some small part of the healthcare system through thoughtful interoperability and better, more “modern” gov tech. I’ll write more about this later, but in the meantime, check out one of the products I’m working on: Data at the Point of Care.
But what else was I up to in 2019? In roughly chronological order:
Early in the year, Programmable Web commissioned me to investigate the technical feasibility of turning away from that neon god we’ve made,3 Facebook, and taking your data with you– and then to figure out what your options are if you do manage to do that. I dove into the delightful, difficult world of the decentralized web and specifically standards and projects around decentralizing social networks.4
Around that time, the European Commission’s APIs4Dgov project brought together a group of researchers and writers, including myself, to prepare a report making recommendations to EU member states on developing their API strategies. I worked on the technical framework recommendations, and in June contributed to a day-long workshop at APIdays Helsinki for folks in gov tech to share knowledge and best practices for implementing government API products. Report to be published this year.
In May, we launched our first REST Fest in Poland, and in September we kicked off our tenth year of REST Fest in Greenville, SC. REST Fest is an unconference dedicated to APIs, hypermedia, and web architecture, and I’ve been involved in organizing it for the past few years. The core principle is that everyone talks, everyone listens, and the goal is to help foster a collaborative, non-intimidating environment to discuss and hack on tools for APIs.
Open Referral, an initiative pushing forward interoperability of health and human services data, has been gaining adoption and over 2019 launched multiple partnerships to implement their Human Services Data Specification (HSDS) and open source tools in different cities. Building on some work I started while mentoring students at HackIllinois (a 2 day college hackathon) in February, I helped code and deploy open source MVPs (minimum viable products) of tools to convert data from unstructured or miscellaneous formats to HSDS-compliant datasets.
So, 2020
I’m tempted to start this section with “Ain’t no rest for the wicked” but alas, that’s not within the song scope of this post. The sentiment, however, still applies.
While I continue full-time at USDS, I’m going to get back into writing here and speaking at conferences. Over my career I’ve done a lot of work adjacent to government – like volunteering with Code for America brigades, consulting for municipalities, and building products for government users – and now that I’m on the inside, I’ll have a lot to share about what I observe and learn.
Questions I’m thinking about right now:
What does “modernization” mean for government technology?
How do we build digital public infrastructure that lasts years or decades that is flexible, adaptive, and user-centered?
How does open source meet or not meet the needs of gov/civic tech?
How can we learn from decentralization to build more effective or more resilient public infrastructure?
I’d love to hear what questions you have too – reach out on Twitter or respond to my newsletter (sign up in the footer at the bottom of this page) to talk.
1
Yes, I got this album on vinyl, because I'm that cool.
2
I wish I could say that this is the last time I use a Simon and Garfunkel song as metaphorical fodder.
3
Okay, okay, I think this is the last Simon and Garfunkel reference in this post.
Note: This is somewhat technical and focused on APIs, but may also be of interest to anyone who cares about how conventions and trends for digital government spread.
I’m in the middle of a research project on government APIs, and as I’ve read more and more examples of API guidelines from governments across the world, it’s struck me how so many of them can trace their roots back to the White House API Standards. Even if I haven’t found evidence of direct lineage from the White House standards to a given API playbook, that playbook usually at least cites the White House repo as a resource or example for further reading.
Origins of the White House API Standards
In 2011, President Obama issued an executive order mandating that US federal agencies had to make web APIs. I can imagine that things got chaotic pretty quickly, with competing conventions struggling for dominance like tortoises crawling on top each other for the sunniest spot on the rock, because the following year someone had the good idea of creating a document of API standards for at least the White House APIs to adhere to.
The White House API Standards repository on GitHub was created on Dec 19, 2012, with a first commit whose message and content was some pretty impressive ASCII art:
The committer is Bryan Hirsch, tech lead at New Media Technologies at the White House at the time. I found this sweet slide deck that he and Leigh Heyman, Director of New Media Technologies at the White House, used to explain the thinking behind their new standards, plus an article about and video of the talk.
The tl;dr is that they created the API standards after working on the “We the People” petition website and related API, in order to make the underlying data concepts easier for non-developers to understand as well as maintain and encourage API best practices over time at the White House and maybe beyond. That beyond definitely happened.
Before I get into that, I think it’s worth documenting here the influences on the White House API Standards:
It’s also worth noting that the White House petition project was built in Drupal, and these standards include Drupal-specific resources and one of the main influences is a talk from a Drupal conference. The standards also still include JSONP examples, although that technology is outdated, insecure, and not generally recommended anymore.
The offspring and third cousins twice removed of the White House API Standards
To trace the family tree that sprung from the White House API guidelines, I started with the GitHub repository’s forks. There are 654 forks, which means that the repo has been copied and potentially extended or used as a base for other projects 654 times. It has 2,621 stars, meaning that many unique users on Github wanted to register their interest in the project. 215 users are watching it, even though the last activity was 4 years ago.
The following governments have made direct forks of the repo:
The fact that 18F (and subsequently the General Services Administration), the Australian Digital Transformation Office, and the UK Government Digital Service all have API guidelines that either directly originate from the WH standards or were influenced by them is pretty significant, because all three of these organizations have been hugely influential in digital government and government API strategy and implementation.
And the influence of this repo don’t stop with the public sector. Plenty of private sector and nonprofit organizations such as Code for America brigades have forked the repo or cited it as an example or influence, including Microsoft and IBM Watson
Most of this was uncovered through browsing and text searching on Github as well as on DuckDuckGo. You could explore this more rigorously with some comparative textual analysis of government API guidelines out there that may not reference the White House repo, but I’m not sure if it’s worth going that far. APIs have gotten more ubiquitous and as more and more governments (and companies) have started implementing API programs, their API conventions have matured and evolved past the White House API standards to include things like design thinking for API product strategy and more detailed recommendations on other aspects of API lifecycle such as security and discovery.
Despite that, it’s interesting to see how much impact these standards have had. As I continue with my research, I’ll probably be able to further trace lines back to 18F, UK Government Digital Service, and Australia, showing the impact that any single organization can have on this tightknit landscape.
“It is a supreme gift to realize that the past is a burden you don’t need to carry with you.”1
In our current digital world, this advice feels both relevant and out of reach. As tech companies follow your every click, view, like, and search across the web, they build profiles of you and assign you a shadow identity even if you “opt out” of tracking, and they effectively make it impossible for you to let the past go.2
Not only is it unclear whether you can ever erase this past, but it’s also incredibly difficult to escape it — both within a single product and across the internet via advertisements. For example: A friend recently searched for “swallow” on eBay in order to find back issues of a food magazine of the same name, and after getting results that were pornographic rather than useful, she continued to see recommendations for the sex-related products for days after. She spent hours scouring the internet and finally talking to eBay support for ways to delete her search history or change recommendations, all to find out that the only path forward was to delete her account and make a new one, a process which could take days or weeks. There are numerous product issues here, but to me one of the most shocking things that even within a single product, users do not have the ability to control what’s saved and used about them.
For another example, take this powerful article from last year in which the author describes how after she suffered a stillbirth, she continued seeing ads targeted at pregnant women. When she reported them as not relevant, she was then shown ads for products for newborns, as though the ad algorithm had assumed that because she was no longer pregnant, she must’ve given birth happily. Facebook responded to this article with instructions on how to opt out of entire ad topics, but that’s just for their platform. How can someone possibly reshape their preferences, history, and identity across the internet when their data is being consumed, analyzed, and used for targeted ads (or other purposes) without their knowledge or consent by companies they may or may not even know about?3
Cities and the burden of their past
A lot has been written about the loss of agency and data ownership of individuals on the internet, and there are projects and legislation underway seeking to address these issues. But what does this mean for communities? For cities?
How does the current state of technology enable or prohibit cities and the people living in them from making their own history, re-making it, owning it, and disowning it?
Note: I’m focusing on cities here rather than communities or other levels of government, because they are a nice little unit with formal governance and plenty of examples to draw on.
Obviously, cities are a bit different than individuals. For one, cities are very much built on the past: they survive for centuries if not millennia, and they evolve and are constantly shaped by past decisions as well as the desires and needs of current inhabitants or stakeholders, whether they are locals or live in Silicon Valley. We see the past all around us: physical infrastructure like buildings, streets, and water systems, and cultural infrastructure, like public art, outdoor spaces, and memorials. We also see different versions of or remembrances of the past coexisting, like statues of Martin Luther King, Jr, sharing space with memorials to confederate soldiers or white supremacists.
And there are many pasts we don’t see: the villages, cities, trade routes, and culture of indigenous peoples erased or displaced by settlers. There are the voices and stories that have historically in this society not been heard or recorded: those of women, indiginous groups, minorities, lower classes, the disabled, and immigrant communities.
This past of a city not something we can or should easily discard, even if it’s a burden we don’t want to carry with us. It is is important to recognize and to seek to understand, because those past decisions impact the present. The construction of highways through historically black or blue-collar neighborhoods not only displaced communities and ensured the future difficulty of revitalizing those neighborhoods, but also led people and money out of cities and into suburbs, shaping American poverty today.
But a city’s past is constantly being reshaped: we reshape it when we uncover the untold stories, when we understand the influences shaping our present, when we make new decisions for our city’s present or future.
The digital history of cities is public data
With tech, we have the opportunity – or misfortune – of having another medium on and with which to write our cities’ and our communities’ histories.
We’re writing the digital history of cities in the same way our personal histories are being written for us online: through data. For individuals, digital history is the personal data that accumulates from our digital activity - the data we intentionally input and collect as well as the data collected about us.
For cities, that digital history is public data, by which I mean data that is generated by the public, though it may not necessarily be publicly accessible. Public data can take a few different forms – and if I’m missing any below, please let me know!
Surveys and observational analysis
For ages cities have been using public surveys to collect data to understand the stories of their communities and inform policies, zoning rules, etc. There are known issues with this, such as sample size, self-selection, truthfulness, and replicability.4 People have to opt in to taking the survey, so surveys are missing the voices of people who opt out, and even when taking surveys, people may not answer truthfully or consistently with what they’ve said in the past. Other tactics involve in-person observational analysis, but that’s only useful when not used in isolation, which I am told is unfortunately often the practice.
Operational data
Operational data is data the city agencies collect in the process of its daily operations. More governments are starting to understand the power of the data they generate simply by doing their jobs, and the stories they can tell with that data.
For example, New York City established the Mayor’s Office of Data Analytics (MODA) to start treating its operational data as a true asset that can help the city improve services, address issues, share data across the city, and implement NYC’s open data law. They are starting to tell the stories of this data and the people involved in its creation, such as those of drivers of for-hire-vehicles and their welfare.
Open data
Public data can be open data. It can be the data that’s available for citizens and companies and other organizations to download and browse or access with an API key. Not all public data that governments collect is actually – or should be – public in the sense of open and freely accessible. That same ride-hailing data that NYC has used to understand and inform policy was shown at one point to contain personally identifiable information which the public would surely not want to actually be public. The balance of privacy and transparency isn’t a problem that’s been solved, but that shouldn’t keep us from trying and promoting open when possible.
While I have heard government tech folks lament at the underutilization of open data portals, open data is critical in the effort for cities to own their narrative and be accountable to residents and themselves.
Social data
Social data can also be public data. An Australian start-up called Neighboulytics has recognized this and is using social data to help cities understand their communities and inform the city decisions. I saw their Head of Analytics, Gala Camacho Ferrari, give a talk at CSV,conf last month,5 and I’m equally cautious and excited about this.
This is an example of people in the community creating their own data and cities being able to read and incorporate that into the city’s story and use it to have a voice in shaping the city. I have a few concerns though:
People post on social media or review sites for a different purpose than city planning, and that context needs to be taken into account when trying to glean insights.
Furthermore, those people may not consent to their data being used that way. They are posting publicly, though, so they have at least dubiously consented to public use (whether they understand that or not is a different question).
Not everyone in the city engages with social media in a way that can be accessed and used, so their voices may not be represented.
That data lives on notoriously closed platforms like Facebook, Twitter, and Instagram (owned by Facebook), so we don’t necessarily know what’s being filtered out or pushed to the top, and those algorithms might impact the way data is presented and read.
Their founder does a good job addressing the some of these concerns in a recent interview, and the last is deeply related to the issue of personal data ownership that we’ve already talked about above. Regardless, I think social data is a valuable piece of the puzzle because it rethinks how cities find and incorporate the voices of their residents.
311 data
Technically 311 data is a subset of operational data and in some cases open data, but it’s worth calling out specifically because it is so important. 311 is the service that can be a hotline or other communication mechanism through which residents in a city can report issues or complaints with city services or neighbors, e.g. noise complaints, tenants rights issues, etc. More than 200 cities in the US have 311, though I’m not sure if cities in other countries have equivalent services.6
I’ve heard NYC government employees call 311 open data the single most important dataset in the city. It is the feedback loop between the city and residents.
Physical data
Cities are physical places, and they generate physical data. There’s been a lot of hype in the past few years about “Smart Cities” and the potential of unlocking the value of this data for cities through smart or wifi-connected devices placed around the city. For example, Syracuse recently announced a $32 million project to upgrade its streetlights to have smart controllers, and these new lights will be the foundation for future projects like sensors to collect traffic data.
At what point does this data collection for public good become privacy-violating surveillance? I don’t want to dive into that too much now, but what I find promising are the emergence of sensor companies like Numina that build devices that do “onboard computing” or “edge processing” – basically meaning that images and other identifying information are processed on the device and sent to the cloud in an anoymized form, and then that identifying information is deleted on the device. To me, this is the only acceptable and responsible way to do public Internet of Things data collection that I know of.
Geographic data
Another type of public physical data is geographic data. Also known as map data or geospatial data, this type of data is public because it describes the world that we all share. This may not necessarily include geospatial data describing private property, but it does include data describing streets, parks, locations of public institutions, etc. Cities and governments typically have departments responsible for a geographic information system (GIS) with detailed geographic data of their jurisdiction, though that data has historically been difficult or costly for the public to access.
Maps are an important part of the public data conversation because they are a “tool of both recognition and oppression.” I dive into this a bit more below, but for some positive news and a historical look at the social impact of maps, check out this article about a new mapping project called LandMark that aims to map and therefore help protect indigenous land.
Shaping public data with an eye towards equity
Data itself isn’t objective, and the act of collecting data isn’t enough. The stories we can tell from data are shaped by the way we collect the data, and what data we choose to collect. For example, if we collect data about medical service use and only collect binary gender options (male and female, rather than additional options such as trans-male and trans-female), then we are missing insight into the medical needs of the trans community.
Taking the same approach with 311 data, if we don’t overlay service request data with socioeconomic, demographic, or location data, we may miss valuable insights into why certain requests seem more prevalent than others. Studies like this one have shown that socio-economic and demographic factors do play a role in who is more likely to make service requests, meaning that we cannot use 311 data on its own to tell a definitive and unbiased story of all city service issues. From a practical perspective, this is important because the city uses this data to determine things like resource allocation and maintenance, and therefore needs to make sure additional data and analsysis are used alongside the raw data to provide context.
The hand that holds the pen
As the characters of the recent film, Colette, like to say, the hand that holds the pen writes history. If public data is the history being written, we have to make sure that the public is the one holding the pen (and the paper). We already see the disturbing consequences of individuals not owning their data or rights to their data in the current tech landscape. This has sobering implications for cities and communities that we can’t ignore.
We’ve already seen multiple instances of communities’s identities being shaped against their knowledge or will because of the power of tech companies like Google in owning and controlling the data that people use. Take for example the recent story about Google erasing a neighborhood and the aftereffects. A community in Buffalo that had referred to itself as the Fruit Belt for generations, suddenly found itself being referred to as “Medical Park” on Google Maps. The source of the name change is complex (read the article - it’s a good one!), but a local geographer and data scientist named Aaron Krolikowski quoted in the article summarizes a key point:
“We’ve historically tended to self-identify our communities…. If suddenly we become disconnected from that process, I think there’s a lot of questions that emerge about the ability of a community to determine its future, in some cases.”
The ability for a for-profit company, which is not accountable to the community (except perhaps when there is bad enough press), to issue an entirely new identity to that community without its consent and with clear economic and social consequences on that community’s shape and future, is a demonstrative and alarming example of the wrong person holding the pen.
We also have to be cognizant of who is making the pen. If the tools being used for civic planning and data collection are built by people who are not representative of the communities in which these tools are being deployed, they will not even be aware of the variations and types of data they need to be able to collect.
This is why many people are reasonably wary of “Smart Cities” programs, especially Alphabet’s Sidewalk Labs project in Toronto. Alphabet is the parent company of Google, and this project involves huge quantities of data being collected. For this project and all the other tech projects involving public data generation, collection, and analysis, we have to keep asking:
Who will truly own that data? Who will decide what types of data get collected, and who is collecting the data? Who is making the tools for this data collection? What policy decisions will this data influence, and what stories will be told from it? How will individuals’ privacy be protected? How will cities ensure this data doesn’t get passed to undisclosed companies to further target ads or seek profit or be used against the will of the public? Perhaps most importantly, how will city residents be able to control and shape that data, delete it when they choose to, and use it for their own self-determination?
1
I saw this quote on a little bronze plaque in a Budapest coffee house called Cafe Madal, though, full disclosure, the wording might have been slightly different. I didn’t take a picture and I haven’t found this in the online archives of Sri Chinmoy, to whom the cafe attributed these words.
“What does digital infrastructure mean to you?” someone asked me last week on a late night walk through DC.
We’d just left federal government grounds, where a cross-organizational, tech-in-gov family games night was hosted in the ceremonial Secretary of War suite. I was buzzing from pizza and non-stop conversation about improving government for the American public.
“APIs,” I said – which, you might already know, is my default answer to any tech question. API stands for Application Programming Interface, and it’s how you exchange data between software systems or servers.
“I’m thinking at a lower level,” he responded. “To me, it’s NPM (a tool for managing JavaScript libraries), or other libraries we use to build software.”
In other words, he meant code, open source or otherwise.
Hardware and the cloud as digital infrastructure
Code is digital infrastructure, and I’ve already written on why I think public infrastructure code should be open source. But there are other layers of digital infrastructure as well: the lowest level of all, technologically speaking, is hardware. APIs help you get data and value out of a system: they enable new workflows and products and unlock value for other parties. But to have APIs, you have to have software and data that can be exposed and used by others. That software lives as code, and that code has to live somewhere.
Traditionally, in government and enterprise industries – from finance to healthcare – that “somewhere” was and often still is a locked-down warehouse, basement, or closet, housing one or many servers that can be accessed through secure networks on-site (e.g. an “intranet”) or, when allowed, by external users via the internet.
Compare that to the “cloud”: The cloud is a bunch of servers that run somewhere else, in a dedicated server farm or data center, and if you want to host your code and data somewhere, you can purchase space in that data center. You no longer have to worry about the physical safety of your servers, like protecting them from natural disasters or making sure they don’t overheat. You also don’t have to worry about scaling: if you need the servers to do more or hold more data, or you need more users to be able to make requests to your servers, you don’t have to buy the new hardware (or physical space) and provision it yourself. You can simply click a button, pay a little more, and voila! You’ve got more server space and capability almost instantly.
The question of whether governments should self-host software that is public infrastructure or host it in the cloud, is complex. I see two main reasons why:
Self-hosting is extraordinarily expensive, especially with the existing procurement process and government vendor landscape.
The existential threat to democracy that monopolistic private hosting companies pose, especially the elephants in every room: Amazon and Google.
Governments very often still “self-host,” but what this usually means is pissing away money to an endless number of contractors (including multiple layers of companies who simply re-sell the software or services of other companies) who manage and maybe sometimes own the data centers. It’s an expensive and inefficient byproduct of the bloated, spaghetti-like procurement process. I’m generally trying to be less uncouth (more couth?) but honestly this makes me so angry and the phrase “pissing away” feels right in my soul.
Governments can save millions or billions of dollars by moving their code to be hosted in the cloud. This would also give better service to the People through more reliable, faster, and sometimes more secure websites that provide public services.
But, and this is a big but: if hardware is a necessary component of digital public infrastructure, should that hardware be publicly (i.e. government) owned?
I think the answer is maybe, but it has to be done differently than it is now. Procurement is part of digital infrastructure too, and the existing processes need to be improved if not overhauled completely.
And if that hardware is not publicly owned, is it okay for government software to be hosted on just one, maybe two, cloud hosting providers?
The answer to this question is emphatically no.
This is a critical question to ask in this moment, because one cloud hosting provider is currently beating out all the others and is frequently cited as the best-in-class, de facto hosting platform: Amazon.1 Amazon Web Services (AWS) has over a 35% market share of the cloud,2 and there are only two significant competitors: Microsoft Azure and Google Cloud. An argument could even be made that the bigger a cloud provider is, the cheaper and more efficient its services are, which, some might argue, is better for everyone. Why have more than one big cloud, let alone three big clouds?
Right now I’m generally for government services to be moved to the cloud, but it cannot be to a single cloud. If all government services were hosted on AWS, this would pose an incredible risk to the People: If Amazon failed, then government might fail.3 And even scarier, if Amazon could influence or turn off government by increasing costs or shutting down services, they could hold government, and therefore the People, hostage.4
Government cannot rely on a single cloud that it does not own. We need clear guidelines and policy for diversifying the clouds that make up the hardware layer of digital public infrastructure.
But it’s not just within the public realm that we have to be wary of clouds that are too big to fail or so big and closed that they can exert undue control without oversight. Our economy and society are increasingly run in digital or online spaces, and those spaces, while not physical, are public spaces. The digital infrastructure underlying them needs thoughtful oversight, regulation, and maintenance just as we would expect for roads, parks, and brick-and-mortar businesses. We need a plethora of digital options for hosting our businesses, accessing services, communicating with our social networks, and sharing photos from last week’s Corgi meetup in Central Park, and we need to be able to leave a platform if we don’t like what they’re doing with our data or the rules they impose on the types of software we can host.
We need policy and anti-trust regulation to protect the People (read: the consumers, the citizens, the residents, the people who just want to get on with their day) from privately held, monopolistic cloud infrastructure.
On a more technical note, this is why I’m also a proponent of Docker, containerization, and serverless technologies, which make it possible and, ideally, easy to move from one cloud provider to another. That way, even if you end up on AWS or Google Cloud, you can re-deploy your code to a different provider, or your own servers, in days or even hours if you need to. If these words don’t mean anything to you, just remember that portability of code and data is critical if we’re going to use cloud providers.
I’m also super excited about distributed and decentralized technologies to help solve this problem, which I’ll write about later.
Trust is digital infrastructure
So far I’ve talked about how hardware, the cloud, procurement, and anti-trust regulation are key components of digital (public) infrastructure. But underlying all public infrastructure, digital or otherwise, is trust.
We trust that restaurants are being reviewed by the Department of Health to make sure they’re sanitary and safe, and we trust that, barring some cases of discrimination and minor corruption, these reviews are honest and in the best interest of the public. We trust that the bridge we drive over to get to work is being maintained and audited for safety on a regular basis by dependable civil servants (or contractors being managed by civil servants), so that it won’t collapse while we’re on it. We trust – maybe – that when we enter our social security number into a government website, that that number and accompanying sensitive information about us is safe from hackers.
It’s worrying to me that I have to insert the “maybe.” Government technology is so far behind private sector technology, from user, product, and tech perspectives, that it makes sense why people trust private companies more when it comes to technological sophistication and security. Tech companies got into people’s hands and onto people’s screens first. It makes sense to be a little cautious, or skeptical, but we should also have that skepticism when we interact with private companies’ tech too.
The key difference between private companies and government that somehow seems to be forgotten is that, in a democracy or republic at least, the People own the government and can influence and change how it’s run. When we don’t think gov tech is up to the task, we can vote for politicians and legislation to change that and we can meet with or become civil servants who tackle those problems. When we lose faith in Facebook or Google, we are powerless to change those companies, especially if/when there are no other options for us to turn to to conduct business or online social activity.
It’s therefore also worrying to me when governments choose to trust private companies rather than build trust directly with citizens; for example, when a government website asks you to sign in using your Facebook login. While whoever made the decision to have that authentication feature probably had good intentions (such as attract a younger demographic or make it easier for users by not adding to account credentials they have to remember), this is a failure of gov tech because the government is abdicating the privilege and responsibility of trust. It outsources identity management, which is surely a key function of government, an indicator of authority, and a requirement for trust in any transaction, to a private-sector company. Not only a private-sector company, but Facebook, the company that is increasingly perceived (rightfully, in my opinion) as not only creepy, but unethical and certainly untrustworthy.
When we build civic or gov tech, we cannot give up trust. We cannot build tools or companies that ask the People to trust those tools and companies over or instead of the government. As democratic institutions, we have to actively build trust, ask for it, and earn it. It’s the most critical piece of infrastructure, and we cannot lose it to private companies instead.
1
For some examples of Amazon's cloud reach even four years ago, see this Atlantic article
2
You can read more here about the research behind that number.
3
And we’ve already seen the pain caused by political goverment shutdowns.
4
One could argue that vendors currently hold the government hostage through the procurement system, but I’m not going to dive into that right now.